
Top down operator precedence(再帰下降構文解析 Pratt Parser)におけるExpression(式)の解析、AST(抽象構文木)構築 処理を追う
Top down operator precedence(再帰下降構文解析 Pratt Parser)におけるExpression(式)の解析、AST(抽象構文木)構築 処理を追う
Goで作る インタプリタ

死ぬほどおすすめなので是非、
Goの基礎とTDDの基礎、簡単なデザインパターンの理解があるとよりよい。むしろそれらを知っている人にかなりおすすめの本である。
この本に出てくる Pratt ParserによるASTの構築の理解が多少難解に感じたので、処理を図とともに追っていこうと思う。
前提
lexical Analyze(字句解析)は完了している。
今回作っている言語には、
Prefix Operator(前置演算子)とInfix Operator(中置演算子)は存在し、
Postfix Operator(後置演算子)は存在しない。
Top down operator precedence とは?
>情報科学の分野において、 Prattパーサ は文法規則の代わりにトークンの意味ごとに関連付けを作るように改良された再帰下降構文解析のひとつ。 https://ja.wikipedia.org/wiki/Prattパーサ より
簡単に説明するとTokeのタイプごとに構文解析の関数を呼び出し、Abstruct Syntax Tree(抽象構文木)(以下 AST)を形成する
Expression (式)とは
名前の通り式のことを指す。
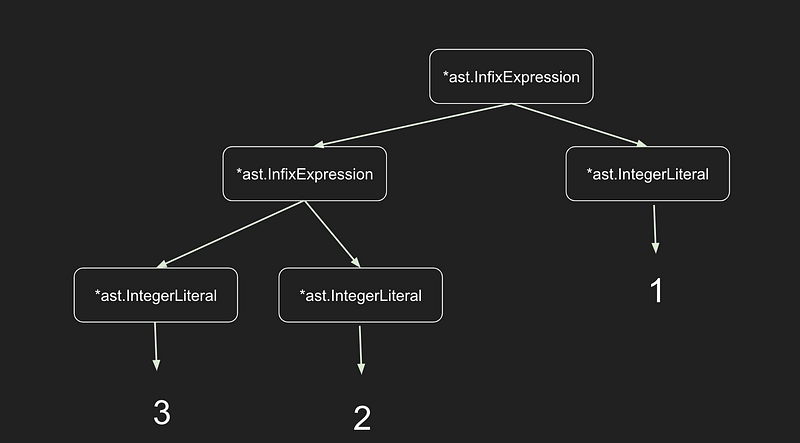
例: 3+ 2+ 1;
8 単体でも式となる。
ちなみに、let x = 5 + 3 + 5;の場合は 式が 5 + 3 + 5;であり
文が let x = 5 + 3 + 5; となる。
今回のASTはこれを ((3+2)+1)と表現したいのである。
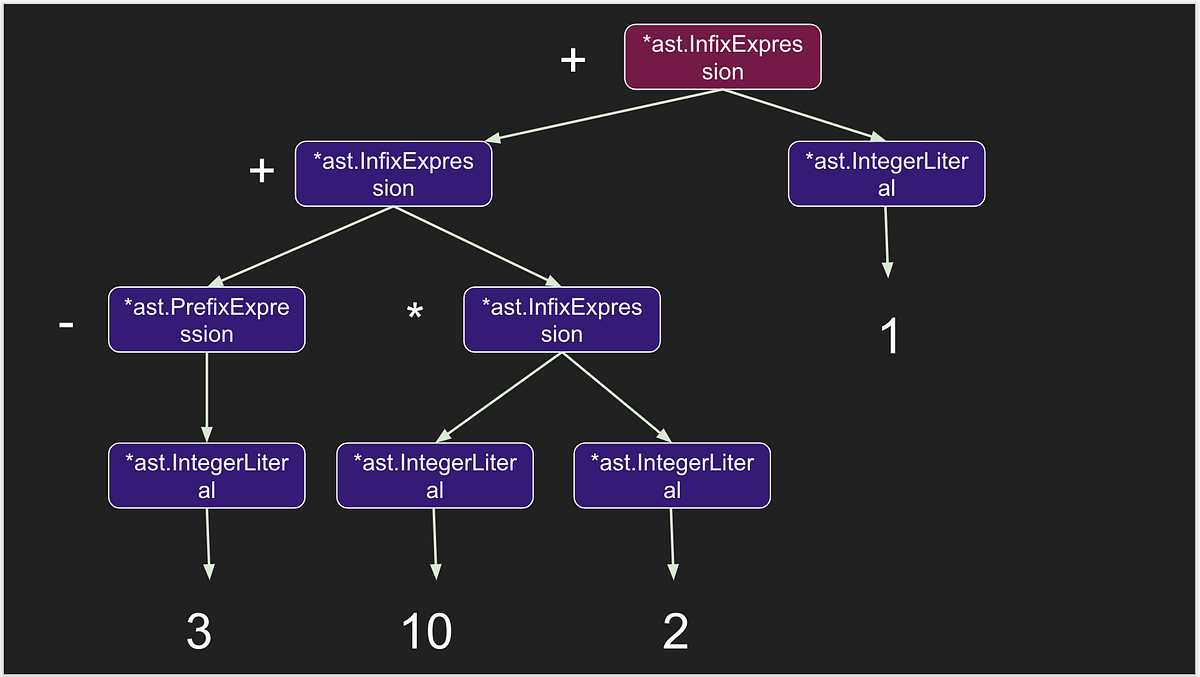
今回見ていく例は
-3 + 10 * 2 + 1;
の構文解析となる。
(((-3) + (10 * 2)) + 1);を表すASTを作っていく。
図式すると。
Main Codes
Precedence (優先度)
例: +(SUM)より *(PRODUCT)のほうが数値が高いので優先度が高い。
 262588213843476
262588213843476
const (
LOWEST iota + 1
EQUALS // ==
LESSGRETER // > or <
SUM // +
PRODUCT // *
PREFIX // -X or !X
CALL // myFunction(X)
)
var precedences = map[token.TokenType]int{
token.EQ: EQUALS,
token.NOT_EQ: EQUALS,
token.LT: LESSGRETER,
token.GT: LESSGRETER,
token.PLUS: SUM,
token.MINUS: SUM,
token.SLASH: PRODUCT,
token.ASTERISK: PRODUCT,
}
最初に呼ばれるコード
262588213843476
func (p *Parser) parseExpressionStatement() *ast.ExpressionStatement {
stmt := &ast.ExpressionStatement{Token: p.curToken}
stmt.Expression = p.parseExpression(LOWEST)
if p.peekTokenIs(token.SEMICOLON) {
p.nextToken()
}
return stmt
}
func (p *Parser) parseExpression(precedence int) ast.Expression {
prefix := p.prefixParseFns[p.curToken.Type]
if prefix == nil {
p.noPrefixParseFnError(p.curToken.Type)
return nil
}
leftExp := prefix()
for !p.peekTokenIs(token.SEMICOLON) && precedence < p.peekPrecedence() {
infix := p.infixParseFns[p.peekToken.Type]
if infix == nil {
return leftExp
}
p.nextToken()
leftExp = infix(leftExp)
}
return leftExp
}
func (p *Parser) parseInfixExpression(left ast.Expression) ast.Expression {
expression := &ast.InfixExpression{
Token: p.curToken,
Operator: p.curToken.Literal,
Left: left,
}
precedence := p.curPrecedence()
p.nextToken()
expression.Right = p.parseExpression(precedence)
return expression
}
func (p *Parser) parsePrefixExpression() ast.Expression {
expression := &ast.PrefixExpression{
Token: p.curToken,
Operator: p.curToken.Literal,
}
p.nextToken()
expression.Right = p.parseExpression(PREFIX)
return expression
}
func (p *Parser) parseIntegerLiteral() ast.Expression {
lit := &ast.IntegerLiteral{Token: p.curToken}
value, err := strconv.ParseInt(p.curToken.Literal, 0, 64)
if err != nil {
msg := fmt.Sprintf("could not parse %q as integer", p.curToken.Literal)
p.errors = append(p.errors, msg)
return nil
}
lit.Value = value
return lit
}
PeekTokenは次のToken
curTokenは現在のTokenを見る
ちなみに 3 + 2 + 1; を動かすと
262588213843476BEGIN parseExpresssionStatement
BEGIN parseExpresssion
BEGIN parseIntegerLiteral
END parseIntegerLiteral
BEGIN parseInfixExpression
BEGIN parseExpresssion
BEGIN parseIntegerLiteral
END parseIntegerLiteral
END parseExpresssion
END parseInfixExpression
BEGIN parseInfixExpression
BEGIN parseExpresssion
BEGIN parseIntegerLiteral
END parseIntegerLiteral
END parseExpresssion
END parseInfixExpression
END parseExpresssion
END parseExpresssionStatement
こんな順番で関数が呼ばれASTが作成される。
結論から言うと、このgifの流れでASTが作成されていく
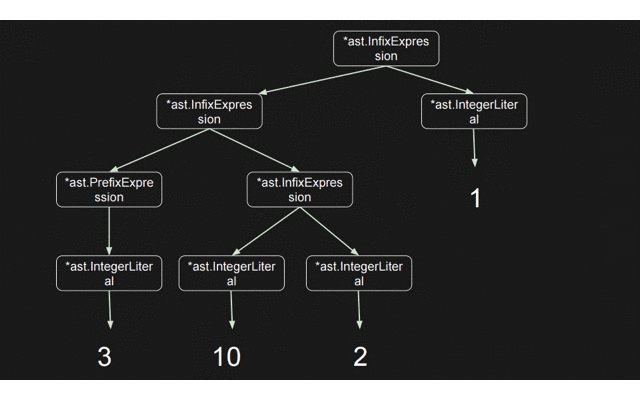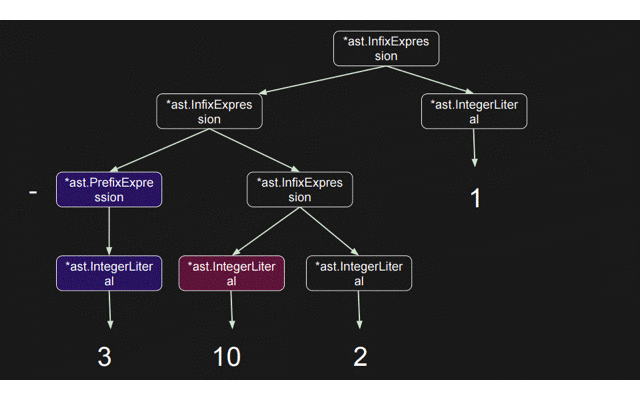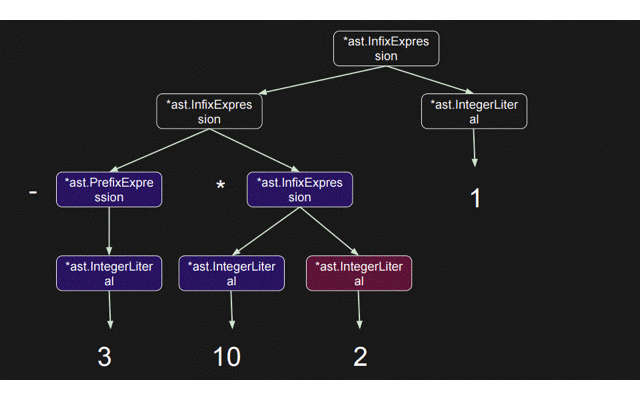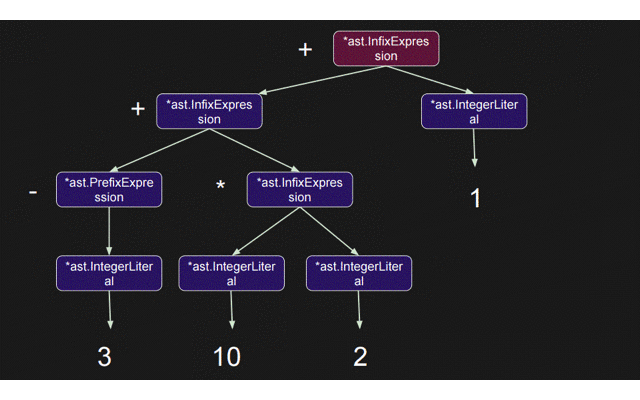
では実際に3 + 10 * 2 + 1; を解析しASTを作っていく処理の流れを見ていく。実際に関数の呼ばれる順番は以下の通りとなる
parseExpression が読んでいる paseIndexExpression などが parseExpression を読んでいる点に注目してほしい。
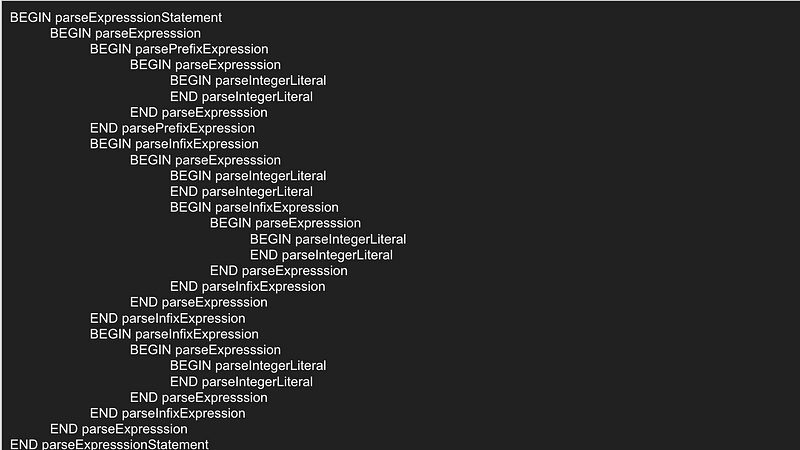
実際にどの箇所の parseExpression が呼ばれいているかこんがらがらないようにIDとして parseExpression に数値を降っておいた。
以下のSlideに細かい流れは乗ってある。